


Four Years In Open Source
Table of Contents:
It’s been another big year in terms of open source contributions and, as is tradition, I wanted to reflect back on the past year to talk about a few highlights on that front. I logged hundreds of hours in open source work between several projects, so I’ll do my best to condense the material by plucking out a few of my favorite contributions.
As I’ve done for A Year In Open Source, Two Years In Open Source, and Three Years In Open Source, I’ll start by sharing a few great programming articles and books I read this year:
Best Reads Of The Year
I didn’t read as much this year, but I really enjoyed a few things in particular:
- Tidy First? by Kent Beck, which also inspired Refactoring By Tidying
- Domain Modeling Made Functional by Scott Wlaschin — the highlight of my year with respect to programming/reading. A must-read for anyone looking to better understand the key concepts behind functional programming; where functional programming and Object-oriented programming overlap; what an f# program looks like. f# is a delightfully expressive language and this book is a gem
- Logging Best Practices — the Honeycomb tech blog never fails to disappoint. I’d also recommend Good Pair Programming Sessions from this year’s lineup of articles
Contribution Highlights
A couple of highlights from the year:
- Lightning Debug & Debug Trace plugin — we, as a team, use this plugin on a daily basis to toggle Lightning Debug Mode on/off, and to easily create/update traces from the command line. It’s been a major time saver!
- Added simple SOSL support to apex-dml-mocking — our team finally had a great use-case for SOSL this year, and this PR added the ability to easily mock SOSL queries
- Apex Rollup: Added Rollup Grouping support — in another year, this might have been the contribution highlight; the ability to group rollups (to do things like a SUM of SUMs, an AVERAGE of several SUMS, the MAX of several SUMS, etc…) ended up being an awesome refactoring exercise that hinged on these sixteen lines of code to add. This was a community request from Systems Fixer on Discord (first made in 2023), and I was quite glad to be able to pull this one off
- VS Code: Added the Collapse All button to the Salesforce VS Code Apex test pane — I still plan to revisit this project to make tests collapsed by default, but I use this feature every single day and I hope you’re aware of it!
- Nebula Logger: Logger Performance Improvements — I attended an in-person hackathon at the end of 2023 during which I was planning to show off some toy scripts, including one that generated a couple thousand log entries using Nebula Logger. I ended up nixing that idea because it turned out that there were some performance issues to work through; it took me a few months, but I got back around to it and was able to improve logging performance by 50-80% for large data volume transactions. If you’re interested in learning more about how I benchmarked performance for this PR, there’s some related reading in The Road To Tech Debt Is Paved With Good Intentions, as well as Benchmarking Matters
- Apex Rollup: Improve Memory Management for LDV Full Recalculations — without a doubt, the highlight of the year, though it also provided me with no small amount of stress. Let’s take a deeper look at the changes involved:
Apex Rollup: Large Data Volume & Full Recalculations
Before beginning to work on this feature, let’s start by reviewing what the architecture looked like:
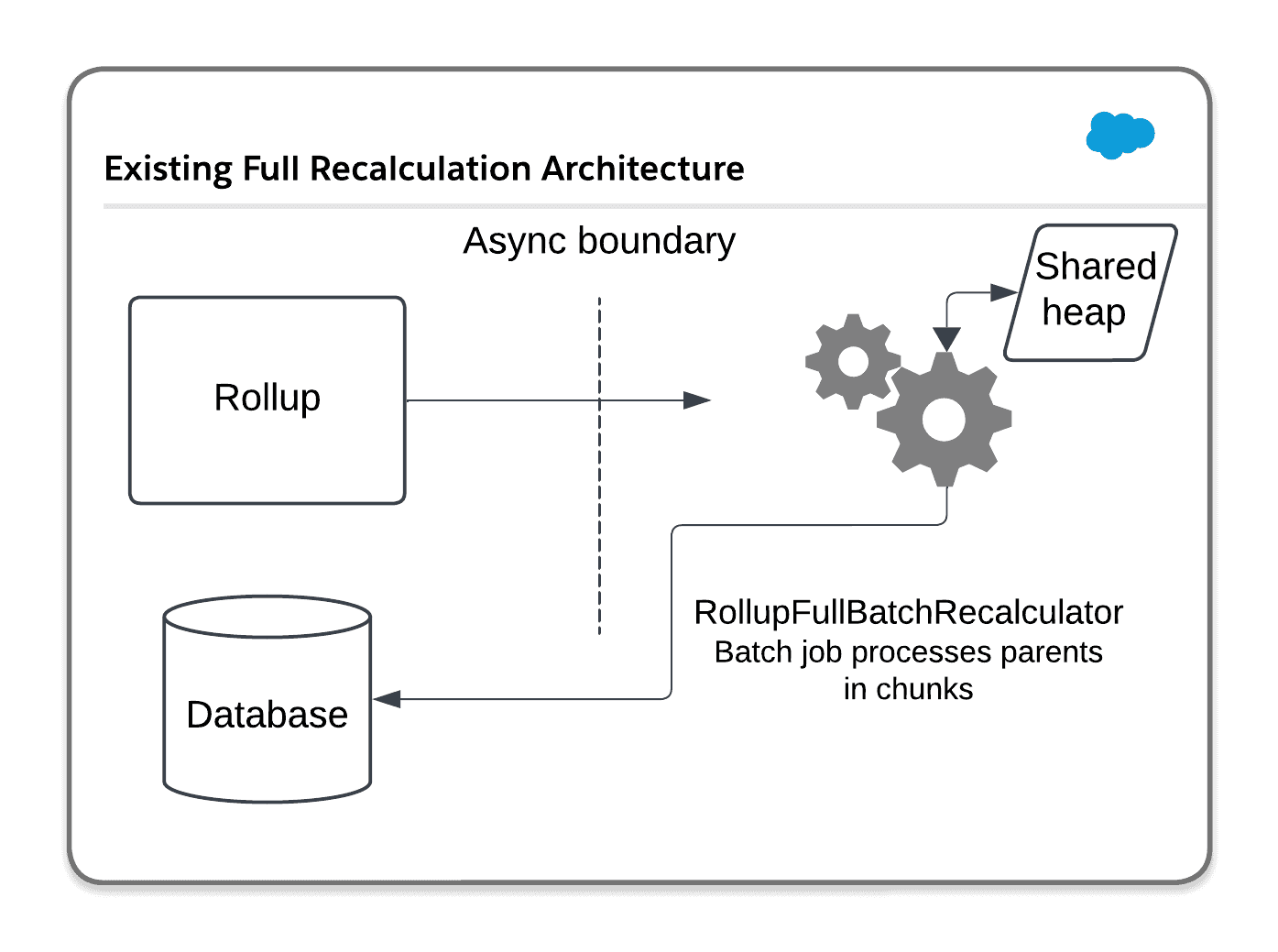
Notice that “Shared Heap” node? The Apex async heap size has a hard limit of 12 megabytes per transaction. Previously, I’d hoped that by using compression, I could keep the data required to perform full recalculations in memory the whole time. What sort of data does that look like? Well, let’s consider what a full recalculation looks like, and how it operates.
When an organization first installs Apex Rollup, or when they first configure a new rollup operation, they need to run a full recalculation to sync the pre-existing values from children records “up” to their respective parent records. This is the equivalent of a SQL group by operation, right? The problem that other frameworks run into is that such query-based summations carry with them their own limits, and those limits are quite low if you’re working in an environment with Large Data Volume — tables with more than 50,000 records, let’s say. In addition, because batch apex “chunks” however many rows you’re looking to operate on, some kind of memory-management strategy is needed. To demonstrate why, let’s review the following table:
| Batch chunk | Child Record Id | Parent Record Id | Child Value |
|---|---|---|---|
| 1 | 0031 | 1 | 18 |
| 1 | 0032 | 2 | 3 |
| 2 | 0033 | 1 | 2 |
| 2 | 0034 | 3 | 1 |
| 3 | 0035 | 1 | 1 |
| 3 | 0036 | 2 | 5 |
Assuming that this were a simple average operation, observe that parent 1 has three children records spaced out across three different batches, and that parent 2 has two different children in two different batches. How do we aggregate this data across transactions such that the average for parent 1 is correctly reported as 7 (18 + 2 + 1 /3) and the average for parent 2 is reported as 4 (3 + 5 / 2)? The simplest possible way is often the best way; in this case, the simplest way is to maintain the state associated with the count of records and the sum of their values across transactions.
The Apex Batch class framework offers a marker interface, Database.Stateful that automatically tracks all of the instance variables associated with your batch class when implemented. At that point, starting to track state is as simple as:
// the parent class(es) implements Database.Batchable<SObject>
public without sharing virtual class RollupFullBatchRecalculator
extends RollupFullRecalcProcessor
implements Database.Stateful, Database.RaisesPlatformEvents {
// this class was being used to track a compressed version of the state
// for each parent
private final RollupState state = new RollupState();
}With 12 MB to work with, tracking every change to a parent by default was a risky proposition; in other applications, where the order of children records can be strictly established, you can also maximize heap space by clearing the key(s) for parent records once the parent key changes in each iteration. Because the children associated with different parent records aren’t necessarily in contiguous batch chunks, though, this sort of optimization leads to other downstream issues that ultimately lead to the rolled up values being incorrect.
But even with the child-level data for each parent compressed, because full recalculations can be performed across up to 50 million records and an unlimited number of configured rollups, it was only a matter of time before even 12 MB of space wasn’t sufficient to store all of the calculation data, and that’s the situation I found myself in earlier this year when somebody reported an issue recalculating 40+ rollups across tens of millions of children records.
Starting To Make Changes
When in-memory storage isn’t sufficient, there’s really only one other alternative on-platform: storing the data in a custom object. This introduces a whole host of other possible issues, but the biggest one that I needed to prevent was creating a record per parent. While that would have been absolutely the easiest thing for me to do, because each record in a table eats up storage space for a subscriber, it wouldn’t be a good look to be creating up to 50 million records per recalculation, even if they were going to be immediately deleted afterwards! That could contribute in a big way to a subscriber’s data storage use — in other words, the solution I’d need to work towards would need to compress as much data as possible into a single record.
Here’s the basics of the updated architecture:
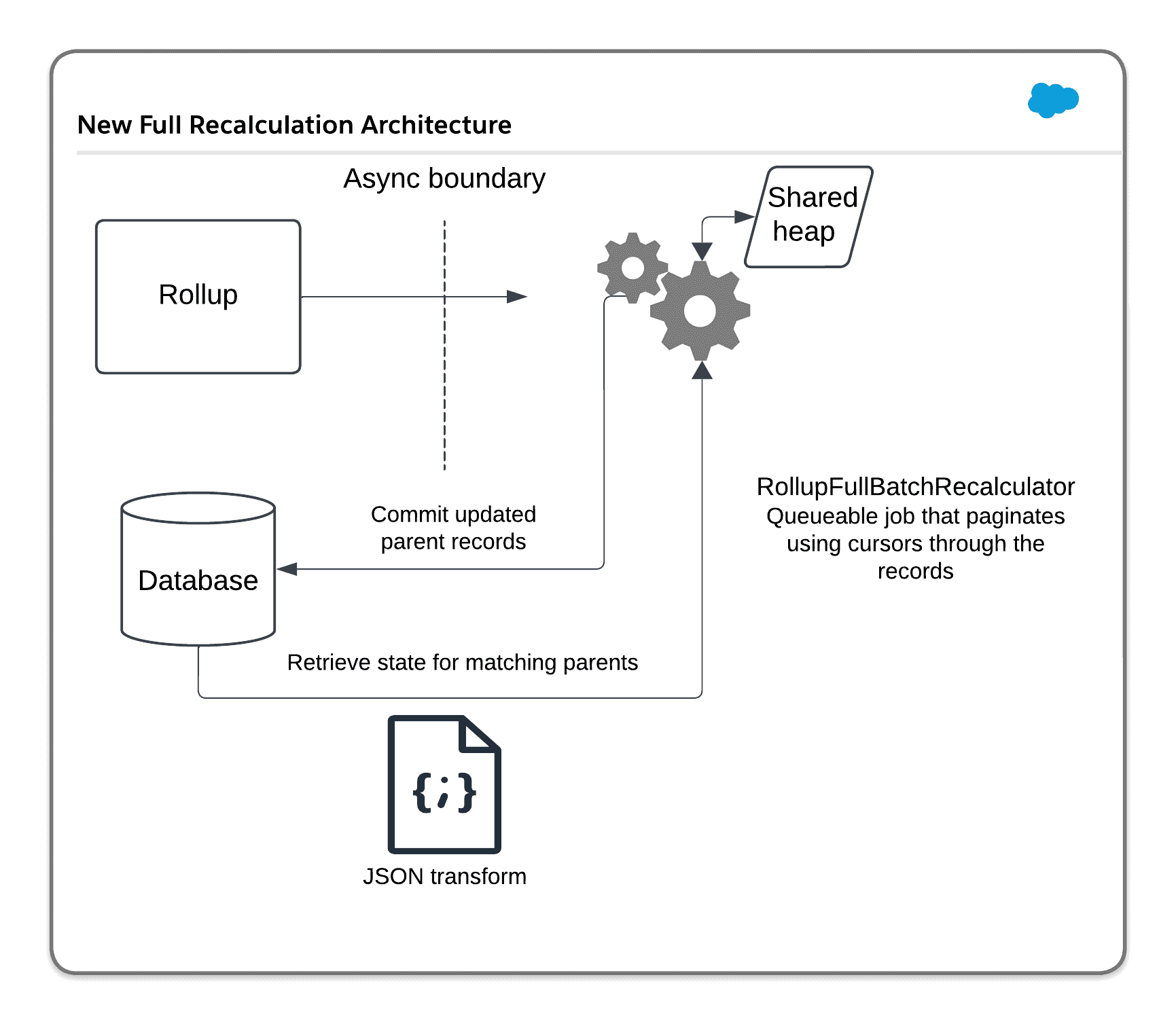
There are a few pieces to break down here:
- Created a custom object, Rollup State, with a long text area field to store the JSON representation of the compressed state associated with the rolled up values for children
- Created 11 different text fields on Rollup State to store comma-separated lists of parent record keys — because you cannot filter on long text areas in SOQL, and because the max length for common text fields is 255 characters, these fields proved crucial in allowing for a large number of parent records to end up being stored on a single record
- I originally wanted to use multi-select picklist fields for this — shocking, really — but you can have a maximum of 1000 distinct values in a picklist and that wouldn’t have worked with multiple concurrent full recalculation jobs running at the same time
- experimented with using Custom Indexes to index the text fields but found that the index doesn’t update fast enough for this kind of use-case
- Migrated to using Database Cursors due to some oddities with how Stateful Batch Apex was handling the tracking of previously retrieved Rollup State records
- There’s a JSON manipulation piece now when reading records from the database in order to transpose them back to in-memory versions of
RollupState. The naive implementation for this is, of course, to simply useJSON.deserialize()… read on to discover why that proved impractical - Various miscellaneous changes were needed to the overall Rollup framework to support these changes; I won’t get into these in too much detail, but I used this PR as an opportunity to both clean up some existing code and take greater advantage of Queueable finalizers, which I wrote about separately in You Need To Use Queueable Finalizers
Retrieving Rollup State
To sum up most of the first bullet point above, consider the method that now retrieves stored state records:
@SuppressWarnings('PMD.ApexCrudViolation')
private List<RollupState__c> loadOrRetrieveCachedState(String jobId, Set<String> relatedRecordKeys) {
String cacheKey = String.join(relatedRecordKeys, '');
List<RollupState__c> states = CACHED_STATES.get(cacheKey);
if (relatedRecordKeys.isEmpty() || states != null) {
RollupLogger.Instance.log('Returning state from cache for record size: ' + (states?.size() ?? 0), System.LoggingLevel.DEBUG);
return new List<RollupState__c>();
}
List<String> quotedRecordKeys = new List<String>();
for (String recordKey : relatedRecordKeys) {
quotedRecordKeys.add('%' + recordKey + '%');
}
states = [
SELECT Id, Body0__c
FROM RollupState__c
WHERE
(RelatedRecordKeys0__c LIKE :quotedRecordKeys
OR RelatedRecordKeys1__c LIKE :quotedRecordKeys
OR RelatedRecordKeys2__c LIKE :quotedRecordKeys
OR RelatedRecordKeys3__c LIKE :quotedRecordKeys
OR RelatedRecordKeys4__c LIKE :quotedRecordKeys
OR RelatedRecordKeys5__c LIKE :quotedRecordKeys
OR RelatedRecordKeys6__c LIKE :quotedRecordKeys
OR RelatedRecordKeys7__c LIKE :quotedRecordKeys
OR RelatedRecordKeys8__c LIKE :quotedRecordKeys
OR RelatedRecordKeys9__c LIKE :quotedRecordKeys
OR RelatedRecordKeys10__c LIKE :quotedRecordKeys)
AND RelatedJobId__c = :jobId
AND IsDeleted = FALSE
AND Id != :this.statefulPreviouslyRetrievedStateIds
ORDER BY CreatedDate DESC
];
CACHED_STATES.put(cacheKey, states);
Database.delete(states, false, System.AccessLevel.SYSTEM_MODE);
return states;
}Yes, that WHERE clause is painful; to reiterate, I attempted to use a custom index on a text-based formula field so that I only needed to use a single LIKE clause, but I found while benchmarking multiple instances where matching records weren’t retrieved in time, suggesting that for fast-moving queueables (which can start up in milliseconds following each successive “batch chunk”) the index does not update in time.
By deleting the state records as they’re retrieved (and keeping in mind that the data is already compressed), we can keep data storage usage to an absolute minimum. I found that the IsDeleted flag also wasn’t always updated in time, necessitating a separate collection of Ids to track the data previously consumed.
Storing Rollup State
As it turns out, retrieval was the least of my worries. Storing the data as JSON turned into a complicated issue with a few edge cases. The business logic seemed simple enough:
- spin up
RollupState__crecords as needed when committing state to the database - for each parent within the in-memory
RollupStateobject, check to see if the parent key (typically an Id) has already been tracked for that record - if any of the text Related Record Key fields would overflow by the addition of a new key, step through to the next field until arriving at
RelatedRecordKeys10__c - if the long text area field length would overflow, or if you’re on
RelatedRecordKeys10__cwithout room for a new parent key, spin up another newRollupState__crecord and continue this process until all records have been processed
In practice, the code for this section ended up taking multiple months to fully work through. There were a few performance issues to work through when considering the ideal solution:
- at the end of the process, the in-memory state needed to be serialized in order to be committed to the database. Practically, however, it’s not possible to serialize each piece of state while looping through the in-memory records because serialization is expensive and there can be thousands of serialization operations per transaction, which would blow through the 60 second asynchronous CPU time limit quite easily. In order to properly track how each piece of state was contributing to the overall length of the long text area where the JSON would be stored, I ended up using a calculated heuristic instead:
// much of this is elided
// this excerpt focuses only on
// the body length calculation
Double currentLength = 0;
Integer maxBodyLength = 131072;
for (String key : KEY_TO_STATE.keySet()) {
RollupState state = KEY_TO_STATE.get(key);
Map<String, Object> untypedState = state.getUntypedState();
// 1.1 is enough of a buffer for the serialized version
// with quoted characters and the + 1 accounts
//for commas as the delimiter between state objects
currentLength += (untypedState.toString().length() * 1.1) + 1;
untypedStates.add(untypedState);
// There's some undocumented soft limit to the amount of data that can be stored in a long text area
// so we use another slight buffer to avoid running into the actual limit
if ((currentLength + 1100) >= maxBodyLength) {
// add to a list to be committed
}
}The code for keeping track of the related parent keys is much more intense, and I’ll omit it here for your sake. If you love pain, you can always view the implementation for populateRelatedRecordStates within the repository itself.
Deserialization Woes
While I was still working out the bugs with properly tracking the related record keys for each piece of Rollup State, I found another issue: I was running into CPU timeouts when deserializing the RollupState__c long text area fields back into the relevant RollupState in-memory objects. This is still something that I’m planning to benchmark more fully and to bring up with the Apex team. I was seeing deserialization vary wildly in time, from totally acceptable values like 2 seconds to totally unacceptable values like 40 seconds(!) for the same length of JSON.
To make progress, I knew that Dataweave offered a more performant version of deserialization, so I set out creating a script that would map the proper inner classes within RollupState (which themselves extended RollupState).
Here are the inner classes in question:
public class SObjectInfo extends RollupState {
public SObject item;
public void setItem(SObject item) {
this.item = item;
}
public override Boolean isEmpty() {
return this.item == null;
}
public override Map<String, Object> getUntypedState() {
return new Map<String, Object>{
'item' => this.item,
'itemType' => '' + this.item.getSObjectType(),
'key' => this.key,
'keyLength' => this.keyLength,
'typeName' => SObjectInfo.class.getName()
};
}
}
public virtual class GenericInfo extends RollupState {
public Object value;
public void setValue(Object newValue) {
this.value = newValue;
}
public virtual override Boolean isEmpty() {
return this.value == null;
}
public virtual override Map<String, Object> getUntypedState() {
return new Map<String, Object>{ 'key' => this.key, 'keyLength' => this.keyLength, 'typeName' => GenericInfo.class.getName(), 'value' => this.value };
}
}
public class MostInfo extends GenericInfo {
public Integer largestPointCounter = -1;
public void setValues(Integer newWinner, Object val) {
this.largestPointCounter = newWinner;
this.value = val;
}
public override Boolean isEmpty() {
return this.largestPointCounter == -1;
}
public override Map<String, Object> getUntypedState() {
return new Map<String, Object>{
'largestPointCounter' => this.largestPointCounter,
'key' => this.key,
'keyLength' => this.keyLength,
'typeName' => MostInfo.class.getName(),
'value' => this.value
};
}
}
public class AverageInfo extends RollupState {
public Decimal denominator = 0;
public Decimal numerator = 0;
public Set<Object> distinctNumerators = new Set<Object>();
public void increment(Decimal value) {
this.numerator += value;
this.denominator++;
this.distinctNumerators.add(value);
}
public override Boolean isEmpty() {
return this.denominator == 0;
}
public override Map<String, Object> getUntypedState() {
return new Map<String, Object>{
'denominator' => this.denominator,
'distinctNumerators' => this.distinctNumerators,
'key' => this.key,
'keyLength' => this.keyLength,
'numerator' => this.numerator,
'typeName' => AverageInfo.class.getName()
};
}
}After many iterations in Dataweave — and a curveball thrown by the namespaced package version of Apex Rollup — I was able to arrive at an elegant script for transforming JSON-based versions of these classes (you saw the usage of getUntypedState earlier when I was showing off how the long text area length is tracked; the mapped versions of these objects can then be transposed back to actual instances since the properties match exactly):
%dw 2.0
input records application/json
output application/apex
// if the attributes property, which only exists on serialized SObjects, is present when trying to deserialize
// it leads to the following error: System.DataWeaveScriptException: Error writing item: Invalid field "attributes" for type "{your SObject Type}"
var getCompliantSObject = (item) -> item filterObject (value, key) -> (("" ++ key) != "attributes")
---
// String coercion used to avoid errors like:
// Invalid type: "org.mule.weave.v2.model.values.MaterializedAttributeDelegateValue"
records map (record) -> "" ++ record.typeName match {
// regex here handles namespaced versions of the class name
case matches /(.*\.|)RollupState\.SObjectInfo/ -> {
key: record.key,
keyLength: record.keyLength,
item: getCompliantSObject(record.item) as Object { class: "" ++ record.itemType },
} as Object { class: $[0] }
else -> record as Object { class: $ }
}And, lastly, how the script is invoked after the aforementioned loadOrRetrieveCachedState method is called:
public void loadState(String jobId, Set<String> relatedRecordKeys) {
this.jobIds.add(jobId);
List<RollupState__c> matchingState = this.loadOrRetrieveCachedState(jobId, relatedRecordKeys);
for (RollupState__c state : matchingState) {
if (this.statefulPreviouslyRetrievedStateIds.contains(state.Id) == false && state.Body0__c != null) {
List<Object> localUncastStates = (List<Object>) new DataWeaveScriptResource.jsonToRollupState()
.execute(new Map<String, Object>{ 'records' => '[' + state.Body0__c + ']' })
.getValue();
for (Object uncastState : localUncastStates) {
RollupState castState = (RollupState) uncastState;
KEY_TO_STATE.put(castState.key, castState);
}
}
this.statefulPreviouslyRetrievedStateIds.add(state.Id);
}
}I found that Dataweave didn’t particularly like me casting to List<RollupState>, but that’s also an area for me to revisit to see if I can properly capture the output type, eliminating the cast inside the for loop.
Validating The Changes
I started working on improving state management within Apex Rollup at the beginning of August, and I finally ironed out the issues and merged my changes on 4 November! While it “only” took 3 months, across those three months I ran over 14,960,000 calculations across thousands of parent records. When I was still testing the batch apex framework version of this, I’d kick off a job with 30+ batches, each containing 500 children, and wait ten minutes to run validation scripts — then do the same thing again and again and again, all while making tiny tweaks to the code and/or logging statements.
Nebula Logger came in handy over and over again as well; when it comes to validating large data volume, Apex unit tests’ soft 10 second CPU time limit fails to make the cut, and it can be challenging to lose access to Debug Logs when working in transient scratch orgs. Having log records to look back on helped with everything from benchmarking timestamps to printing out massive quantities of JSON-related text easily. A huge and ongoing thanks to Jonathan Gillespie for the work that he does on Nebula, and another hearty congrats on becoming the third most popular Salesforce repository on GitHub!
Wrapping Up
I’m excited to see what the next year brings when it comes to open source. In reviewing my own contributions for the year, I was blown away that some of these contributions happened this year. Somehow the months fly by but the weeks and days feel quite long. We’ll have to see if I somehow manage to one-up myself next year 😅!
Thanks as always to Arc and Henry for continuing to support me on Patreon, and thanks to my other Patreon subscribers as well! It’s a great time of year to reflect, introspect, and relax — here’s to hoping that you find some time to do so as this year wraps up. If I don’t see you till January, Happy New Year in advance!