


Open Sourcing The Round Robin Assigner
Table of Contents:
First, I’d like to thank Xi Xiao for having me aboard the SalesforceWay podcast — this time to talk about Test Driven Development. It’s somehow been two years since we last met up to talk about mocking DML in Apex, and it was great to catch up and talk shop about a subject I’m so passionate about. Thank you, Xi!
I decided to open source my Salesforce round robin assigner, because I know how difficult it is to get the edge cases right when building something like this, and I wanted to create an easier way to hook into round robin-style assignments for both Flow and Apex developers. I’ll walk a little bit through the changes I made prior to packaging up this functionality, and hopefully leave you with another great free tool. I’d also like to thank Jonathan, who’s provided invaluable feedback and advice on this project since I first began working on open sourcing it in earnest a few weeks ago. If you want to skip ahead, here's the link to the newly open sourced round robin package!
Lessons Learned Along The Way
Like the lessons learned after a year of working on Apex Rollup in open source, there were some fun moments of insight and some frustrating things to deal with along the way. Probably the biggest pain point was in figuring out how to get a cache partition to play nice with packaging/scratch orgs; you can enable Platform Cache via something like the project-scratch-def.json file:
{
"orgName": "Round Robin Assigner",
"edition": "Developer",
"country": "US",
"language": "en_US",
"features": ["PlatformCache"]
}Getting Bit By Platform Cache & Scratch Orgs
… but that only gets you so far. The original implementation of the assigner used the Org.Cache class, and (again, one of my personal faves), the Cache.CacheBuilder interface. This required quite a bit of tweaking; you can’t programmatically set a default cache partition (it can only be done through the Setup menu), and you can’t call any of the Org.Cache methods if a default partition hasn’t been set. This isn’t a problem for orgs actually installing the package, or for scratch orgs created based on the way the project is now, thanks to this piece of metadata:
<!-- in the cachePartitions folder -->
<?xml version="1.0" encoding="UTF-8"?>
<PlatformCachePartition xmlns="http://soap.sforce.com/2006/04/metadata">
<isDefaultPartition>false</isDefaultPartition>
<masterLabel>RoundRobinCache</masterLabel>
<platformCachePartitionTypes>
<allocatedCapacity>0</allocatedCapacity>
<allocatedPartnerCapacity>0</allocatedPartnerCapacity>
<allocatedPurchasedCapacity>0</allocatedPurchasedCapacity>
<allocatedTrialCapacity>0</allocatedTrialCapacity>
<cacheType>Session</cacheType>
</platformCachePartitionTypes>
<platformCachePartitionTypes>
<allocatedCapacity>1</allocatedCapacity>
<allocatedPartnerCapacity>1</allocatedPartnerCapacity>
<allocatedPurchasedCapacity>0</allocatedPurchasedCapacity>
<allocatedTrialCapacity>0</allocatedTrialCapacity>
<cacheType>Organization</cacheType>
</platformCachePartitionTypes>
</PlatformCachePartition>However (and this is such an edge case, but it’s worth talking about) — when I first created the scratch org I was doing development out of for this project, I didn’t have that metadata yet; I only had Platform Cache enabled. What I found out is that if you create a scratch org without having first deployed a cache partition, you end up with a pretty wonky cache.Org.OrgCacheException:
// getCachePartitionName is an abstract method that people can implement
// and in the package, the cache partition name is called using the
// "RoundRobinCache" string that matches the masterLabel in the XML above
Cache.OrgPartition partition = Cache.Org.getPartition(this.getCachePartitionName());
/**
cache.Org.OrgCacheException: Invalid partition - partition 'local.RoundRobinAssigner' does not exist.
(System Code) < -- yes, the error actually prints that snippet out
Class.AbstractCacheRepo.getPartition: line 27, column 1
Class.AbstractCacheRepo.getFromCache: line 15, column 1
Class.RoundRobinRepository: line 86, column 1
Class.RoundRobinRepository.getCurrentAssignment: line 35, column 1
Class.RoundRobinRepository: line 7, column 1
*/So that ended up being a huge red herring, and originally I found (after looking extensively through the scant few other repos on GitHub making use of the Cache.OrgPartition type) a pretty wild hack for defensively dealing with this issue:
private Cache.OrgPartition getPartition() {
Cache.OrgPartition partition;
try {
// this throws if the partition isn't recognize, for whatever reason
Cache.OrgPartition.validatePartitionName(this.getCachePartitionName());
partition = Cache.Org.getPartition(this.getCachePartitionName());
} catch (cache.Org.OrgCacheException orgCacheEx) {
partition = new Cache.OrgPartition(this.getCachePartitionName());
}
return partition;
}So, to whomever first had the bright — and possibly crazy — idea to call new Cache.OrgPartition(myCacheName) as a way to deal with tests not always having access to the cache partition … ✊ I salute you. Luckily, this method now looks a lot less crazy:
private Cache.OrgPartition getPartition() {
return Cache.Org.getPartition(this.getCachePartitionName());
}So that was a fun (if occasionally frustrating) bit of learning; one of those classic “order of operations” things that bit me but can easily be avoided in the future … or was it? I originally wrote these lines a few days ago, and was working to finalize the package leading up to its release on 1 March 2022. While making a seemingly innocuous change, package creation — using the very same code I highlighted above — began failing, again with the cache.Org.OrgCacheException. My only lead in investigating this issue? The time of day. All of the times I’d successfully been able to create a package were in the morning. Bizarrely, the “fix” — which I also showed above, catching the cache.Org.OrgCacheException? It also didn’t work. What was going on?
I’ll have to follow up with more details on this unseemly packaging issue. For now, I’ve implemented a workaround:
@SuppressWarnings('PMD.EmptyCatchBlock')
private Cache.OrgPartition getPartition() {
Cache.OrgPartition partition;
try {
partition = Cache.Org.getPartition(this.getCachePartitionName());
} catch (cache.Org.OrgCacheException orgCacheEx) {
// do nothing - there seem to be some timing dependencies on when
// it's possible to use Platform Cache while packaging.
}
return partition;
}And then in usage:
protected Object getFromCache() {
Object cachedItem = this.getPartition()?.get(this.getCacheBuilder(), this.getCacheKey());
if (cachedItem == null) {
// the item is only null when there's an issue with the packaging org not properly
// creating the cache partition; in this case, we "know" what the value will be
// and can manually load it
cachedItem = this.populateCache();
}
return cachedItem;
}Yikes. Hoping to get some clarity on how to avoid doing that and remove that particular piece of code in a future release!
Thinking About Flow & Apex Together
This isn’t so much a “gotcha” so much as it is a result of the platform’s current capabilities: until Flow can call Apex from BEFORE contexts (before insert, before update, notably), there will always be recursion when attempting to update same-object collections. If people looking to use the round robin assigner from Flow can live with logic running twice — which isn’t a problem in simple flows, especially ones that only feature the assigner invocable — then Flow is already a perfect place to start using the assigner:
All it takes is assigning the $Record variable to a collection variable, and passing it in to the action:
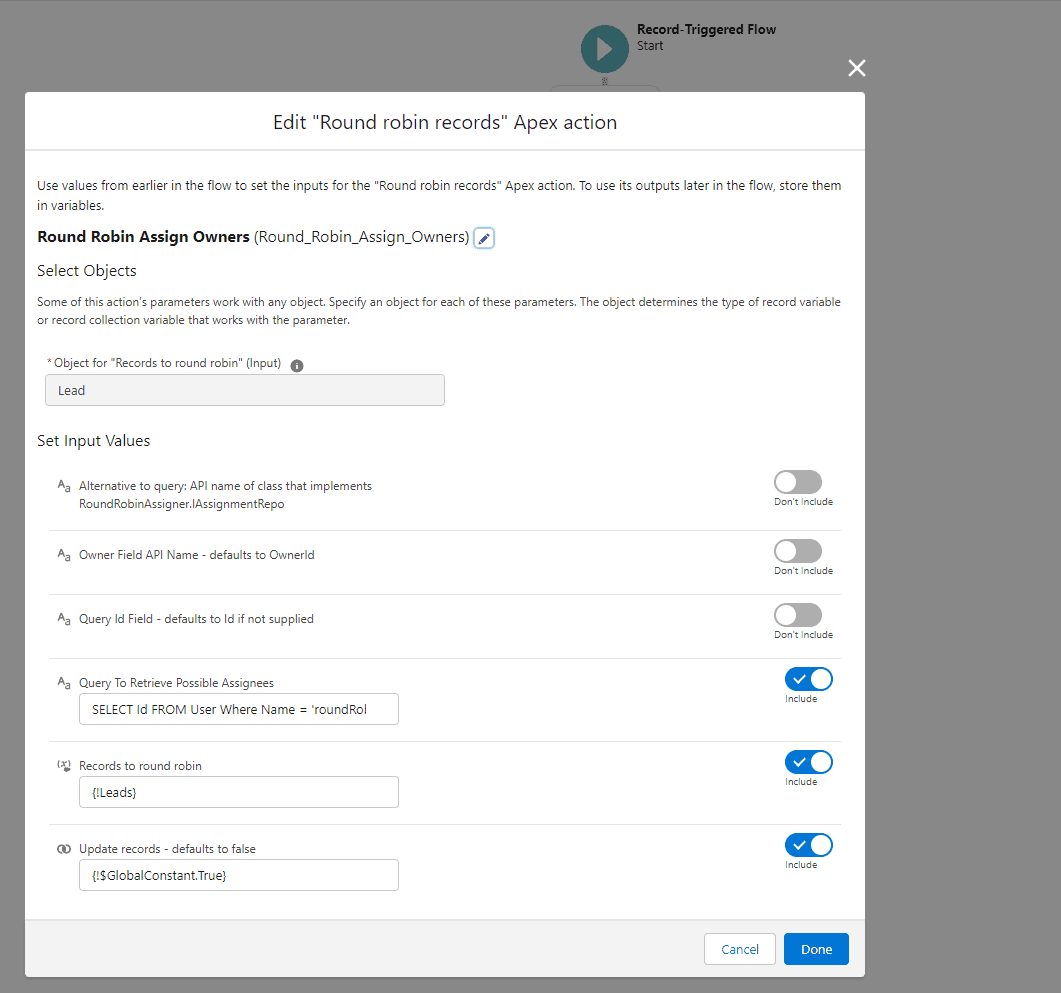
There are a number of invocable properties that can be set by Flow Builders, but the ones that will probably be the most interesting for basic use-cases are:
Query To Retrieve Possible Assignees- This query will pull back records - like Users - and grab theirIdfield (or another Id field stipulated by one of the other optional Invocable properties) that should be included in the “ownership pool” for the given round robin.Records To Round Robin- the collection variable mentioned above, for a Record Triggered Flow, or possibly the output of aGet Recordsinvocation in other flowsUpdate Records- this is what updates the newly assigned records from within the Apex called by the invocable
I am really looking forward to Apex Actions being available within before save Flows! That will truly unlock the power of the round robin assigner from within Flow, without having to worry about introducing duplicated updates.
Architecting A Great Apex Developer Experience (DX)
I was really keen to produce a package that would allow for Apex developers to easily hook into round robin functionality without having to worry so much about the surrounding architecture. This is a place where working on apex-rollup has really come in handy, as I can apply a lot of the learnings from producing something big when working on something considerably smaller.
When it comes to developer experience, there’s an interesting see-saw effect that takes place between:
- ease of access: how complicated are the package’s boundaries to interface with?
- flexibility & power: how much customization is possible? Are the customizations options helpful, or does it feel like something’s missing?
To aid in consumers looking to hook into round robin functionality, I’ve introduced several objects, as can be seen from the class signature:
public class RoundRobinAssigner() {
// ...
public RoundRobinAssigner(IAssignmentRepo assignmentRepo, Details details) {
// ...
}
}Let’s take a look at that first argument, the IAssignmentRepo:
// in RoundRobinAssigner.cls
public interface IAssignmentRepo {
List<Id> getAssignmentIds(String assignmentType);
}First of all — could this be a self-standing interface? For sure, it could be. But I think that defeats the purpose of encapsulation; certainly I have no business dictating within your own codebase the shape of an interface like this outside of round robin assignment; for that reason, it makes sense for this to be an inner interface that’s exposed to consumers. Here’s an example implementation, which happens to be bundled with the application for the purpose of being used with Flow:
public without sharing class QueryAssigner implements RoundRobinAssigner.IAssignmentRepo {
private final List<Id> validAssignmentIds;
public QueryAssigner(String query, String assignmentFieldName) {
Set<Id> assignmentIds = new Set<Id>();
List<SObject> matchingRecords = Database.query(query);
for (SObject matchingRecord : matchingRecords) {
assignmentIds.add((Id) matchingRecord.get(assignmentFieldName));
}
this.validAssignmentIds = new List<Id>(assignmentIds);
}
public List<Id> getAssignmentIds(String assignmentType) {
return this.validAssignmentIds;
}
}In the case of Flow, the assignmentFieldName defaults to Id, but can be customized. Likewise, the reason that the assignmentType argument is provided by the interface (though notably ignored in the example above) is because you could do something like this:
public class ExampleAssignmentIdRepo implements RoundRobinAssigner.IAssignmentRepo {
private final Queue fallbackQueue;
private final List<SObject> ownershipPoolRecords;
public ExampleAssignmentIdRepo(Queue fallbackQueue, List<SObject> ownershipPoolRecords) {
this.fallbackQueue = fallbackQueue;
this.ownershipPoolRecords = ownershipPoolRecords;
}
public List<Id> getAssignmentIds(String assignmentType) {
Set<Id> distinctOwnershipPool = new Set<Id>();
for (SObject ownershipPoolRecord : this.ownershipPoolRecords) {
Id ownershipId;
switch on assignmentType {
when 'Lead.OwnerId' {
ownershipId = (Id) ownershipPoolRecord.get('Id');
}
when else {
ownershipId = (Id) ownershipPoolRecord.get('OwnerId');
}
}
distinctOwnershipPool.add(ownershipId);
}
if (distinctOwnershipPool.isEmpty()) {
distinctOwnershipPool.add(this.fallbackQueue.Id);
}
return new List<Id>(distinctOwnershipPool);
}
}In other words — knowing what sort of assignment is happening is useful information, and exposing that information to consumers allows for them to customize what happens in a way that it wouldn’t be possible for me to anticipate or offer up every option beforehand for.
The secord argument passed to RoundRobinAssigner, RoundRobinAssigner.Details, acts similarly:
// in RoundRobinAssigner.cls
private static final String OWNER_ID = 'OwnerId';
// ...
public class Details {
public String assignmentType { get; set; }
public String ownerField {
get {
if (ownerField == null) {
ownerField = OWNER_ID;
}
return ownerField;
}
set;
}
}I debated adding a constructor for this class so that the assignmentType parameter could be passed in more easily, but I think that having to set the property explicitly after initializing the object makes for better reading:
// this is a bit more obscure
RoundRobinAssigner.Details details = new RoundRobinAssigner.Details('Account.OwnerId');
// than this
RoundRobinAssigner.Details details = new RoundRobinAssigner.Details();
details.assignmentType = 'Account.OwnerId'As well, the assignmentType parameter ends up being used as the caching key for individual RoundRobin__c records. This means that multiple sections of the codebase can interact with the same fair tracking for round robin assignment, so long as they’re passing the same string there (which then also ends up getting passed to the implementers of the IAssignmentRepo, further downstream). I’ve been defaulting to the record type and field name, as per the example that the invocable action ends up using:
// in the invocable, FlowRoundRobinAssigner.cls
private RoundRobinAssigner.Details getAssignmentDetails(FlowInput input) {
RoundRobinAssigner.Details details = new RoundRobinAssigner.Details();
details.assignmentType = input.recordsToRoundRobin[0].getSObjectType().getDescribe().getName() + '.' + input.ownerFieldApiName;
details.ownerField = input.ownerFieldApiName;
return details;
}It’s my hope that by exposing these options (and their sensible defaults), to developers, they’ll be able to quickly and efficiently implement round robin assignments without having to customize anything other than how their ownership pools (of, presumably, valid users to choose from) are defined. That was the logical boundary I was considering while working to open source this, and I’ll be excited to see how people end up making use of this functionality!
Wrapping Up
Again, the salesforce-round-robin package is available for free, forever. It’s my hope that it will end up being useful to people who were looking for round robin functionality when it comes to assignment inside of Salesforce, and either didn’t want to code their own solution, or were looking for a great DX when it comes to implementing something custom. All feedback is welcome, of course, and I intend to keep on top of the GitHub issues/suggestions (should they be submitted!) for this project.
Thanks for reading along — till next time!