


Three Years In Open Source
Table of Contents:
In September of 2020, with the COVID-19 pandemic raging globally, I made the decision to start more actively contributing to Salesforce open source projects. Several months later, I open sourced Apex Rollup, and last year added Salesforce Round Robin to the mix. This year has been largely about supporting the growth of both of these projects, as well as continuing to contribute to and support open source classics like Nebula Logger, which appears on track to join the top 5 most-starred GitHub repositories associated with Salesforce early next year.
Contributing to open source continues to be a rewarding and humbling experience. It gives me the opportunity to give back, continue to learn, and challenge myself all at once. It also forces me to keep abreast of programming-related developments both in my own industry and writ large.
As I’ve done for A Year In Open Source and Two Years In Open Source, I’d like to kick off by mentioning some of the best programming-related reads I’ve enjoyed this year.
Best Reads Of The Year
I spent the first half of this year on a voracious programming-related reading cycle, and these were the articles that I enjoyed the most that I read during that time:
- Slowing Down to Speed Up – Circuit Breakers for Slack’s CI/CD — I haven’t asked my colleague if they were at all inspired to make this title based off of my Move Fast, Don't Break Things, on the Salesforce Developer Podcast podcast title, but regardless it’s an excellent read
- Bridging the Object-Oriented Gap — I love a good iterative approach when it comes to building out one of the GoF patterns, and this one does a great job of showing the expressiveness of TypeScript in action
- How To Run A Remote Team a thought-provoking read on distributed teams
- My favourite three lines of CSS a wild look into the best parts of cascading style sheets!
- Stubs & Mocks Break Encapsulation — really speaks to many of the reasons that I created the Apex DML Mocking library, having also come from C#
Reading is, for me, that best way to allow for continuing education. I recognize that some people are visual learners, or learn by doing, but if you enjoy reading about our craft, this little hodge-podge spans quite a few different genres and there should be something for everyone.
Lessons Learned This Year
I’ve been jotting down notes to myself throughout the year on lessons learned; in a year of great turmoil and economic downturn, keeping an introspective mindset with regards to learning has proven particularly effective in helping me deal with stress and uncertainty. Here are a few of these thoughts, in no particular order:
- if you don’t have the path paved to production, the effectiveness of any given POC wanes quickly.
- nothing kills successful projects faster than a system without use; the corollary might be that the second-biggest killer of projects is the proper lack of executive buy-in. You can have the best product in the world, but if you can’t convince people to use it, you’d better be willing to settle for it simply being beautiful to you.
- the worth of an enterprise is measured by how much money it makes; the worth of an individual is derived by how much satisfaction they make. I can’t underscore this enough. I feel incredibly lucky to have found rock climbing in my teenage years and running in my 20s; to have hobbies that provide me with immense satisfaction, meaning, and friendships — crucial crutches in the face of professional and economic uncertainty. 2023 was a year in which I saw many people I know and care about laid low by layoffs or a decline in business. The people whose ideas of self were thoroughly entrenched in what they did for a living almost always had a harder time of it than those whose hobbies defined them. Monetary success is also no guarantee of happiness: I’ve listened to, watched, and read countless stories of fabulously wealthy people who’ve struggled to make sense of their place in the world. TL;DR — don’t let your work define you
I found this quote about programming earlier this year, and I’ve been looking forward to sharing it:
I think that it’s extraordinarily important that we in computer science keep fun in computing. When it started out, it was an awful lot of fun. Of course, the paying customers got shafted every now and then, and after a while we began to take their complaints seriously. We began to feel as if we really were responsible for the successful, error-free perfect use of these machines. I don’t think we are. I think we’re responsible for stretching them, setting them off in new directions, and keeping fun in the house. I hope the field of computer science never loses its sense of fun. Above all, I hope we don’t become missionaries. Don’t feel as if you’re Bible salesmen. The world has too many of those already. What you know about computing, other people will learn. Don’t feel as if the key to successful computing is only in your hands. What’s in your hands, I think and hope, is intelligence: the ability to see the machine as more than when you were first led up to it, that you can make it more - Alan J. Perlis
This quote stood out to me during a year in which I found the scope of my responsibilities expanding rapidly, leaving me with less time to program hands-on, and more time to think about how to create the best possible environment for others to thrive in. I also think the line “what you know about computing, other people will learn,” was a powerful reminder to keep my own ego in check 😇.
Fun Architectural Decisions
There were a few highlights for me in the open source world this year that I’d like to talk about, because I think they’re interesting and worth sharing. The first was a feature request from the community for Apex Rollup; the second was a long-overdue refactoring of tech debt to properly model a graph-based problem. I’ll also touch on some memory management points at the end.
Architecture Highlight 1: Group By Rollups
When I explain Apex Rollup to somebody unfamiliar with Salesforce, I typically talk about pivot tables — a rollup is a way to define agreed-upon operations that aggregate child-level data to a parent. In a pivot table, that “parent” is a summary row; in Salesforce, that “parent” is a record. This year, the person AKA’d as “Systems Fixer” approached me with an interesting request for a more advanced rollup configuration that allowed users to stipulate additional grouping fields when configuring rollups such that the output could aggregate the data for an operation using those grouping fields as well.
There are two reasons why I found this to be a fascinating feature:
- A traditional rollup takes a list of children and acts as a reducing function on a discrete field associated with those children; it creates a single summary value. A grouping of those values almost inevitably takes the form of a string. This was an intriguing challenge
- Because Salesforce supports both long text and rich text area fields, this inevitably begged the question: could we do this with tables?
Before diving into the code, I want to highlight how a traditional rollup appears versus a group by rollup. This is what a non-grouped by rollup looks like when it’s been configured:
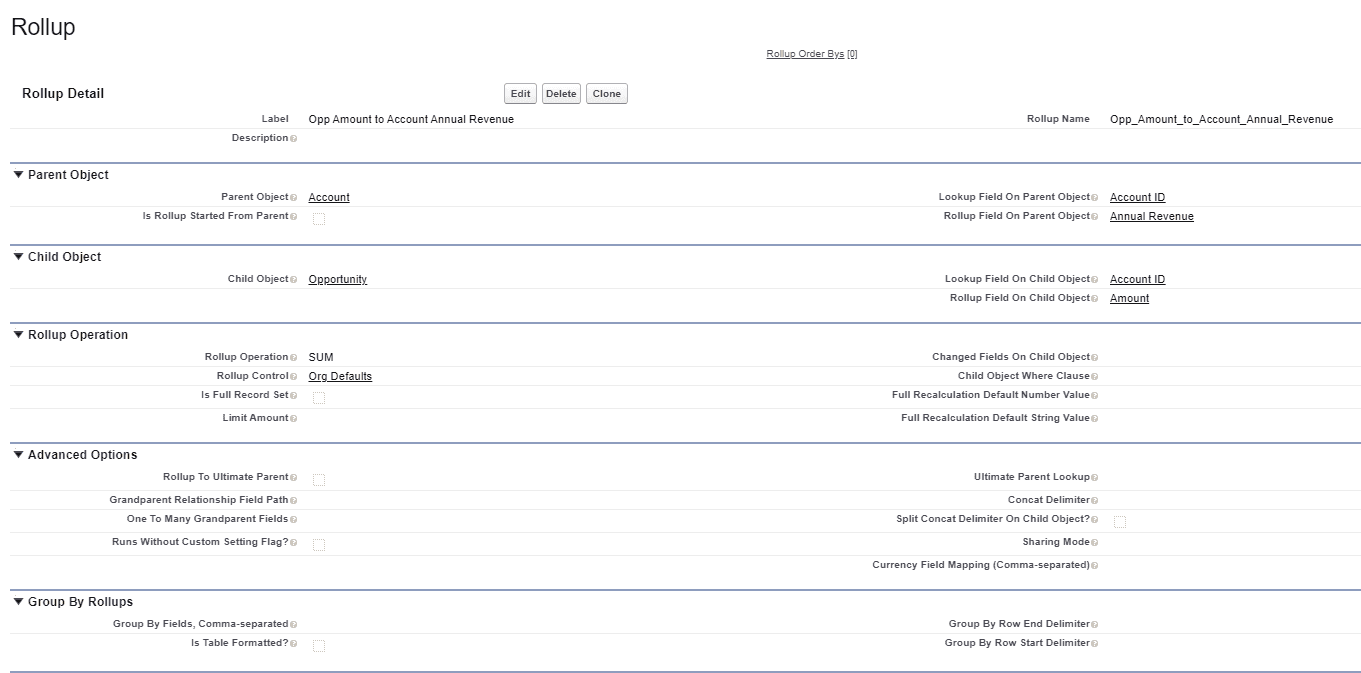
That would lead to something like this on an Account record with a few opportunities:

But let’s say that I edit where the rollup field should be output to, and add a bit of info to the Group By section of the config:
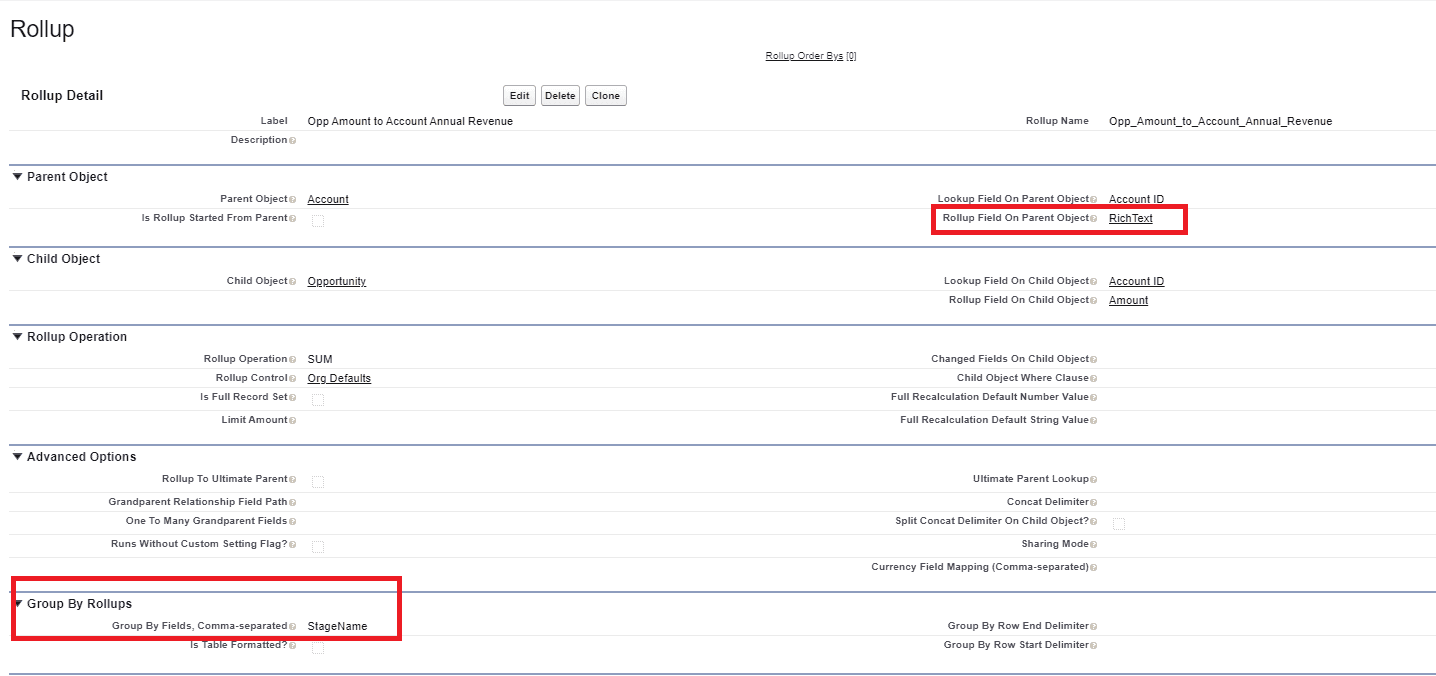
If I recalculate the rollups for this parent, I now see this:

If I tick the “Table Formatted” option in the config, I get to see something like this gem in the logs between runs:
lookup record prior to rolling up:
{
"Id" : "someId",
"RichText__c" : "• Prospecting, 57000.00<br>• Qualification, 52000.00<br>• Needs Analysis, 291000.00<br>• Value Proposition, 53000.00<br>• Id. Decision Makers, 168000.00<br>• Perception Analysis, 56000.00<br>• Closed Won, 149000.00"
}
lookup record after rolling up:
{
"Id" : "someId",
"RichText__c" : "<table><tr><th>Stage</th><th>Amount</th></tr><tr><td>Prospecting</td><td>57000.00</td></tr><tr><td>Qualification</td><td>52000.00</td></tr><tr><td>Needs Analysis</td><td>291000.00</td></tr><tr><td>Value Proposition</td><td>53000.00</td></tr><tr><td>Id. Decision Makers</td><td>168000.00</td></tr><tr><td>Perception Analysis</td><td>56000.00</td></tr><tr><td>Closed Won</td><td>149000.00</td></tr></table>"
}Which ends up looking like:
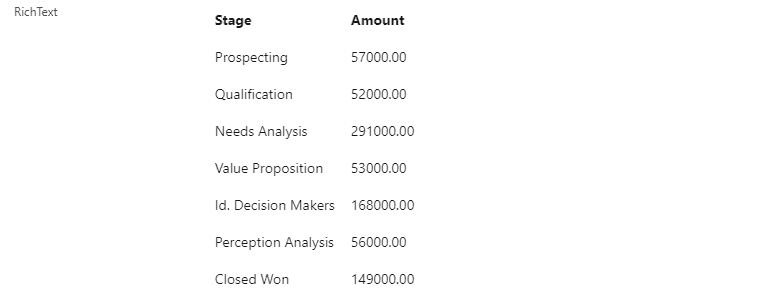
Which is pretty freaking cool. I can add additional grouping fields, comma-separated, to the configuration:

Which leads to:
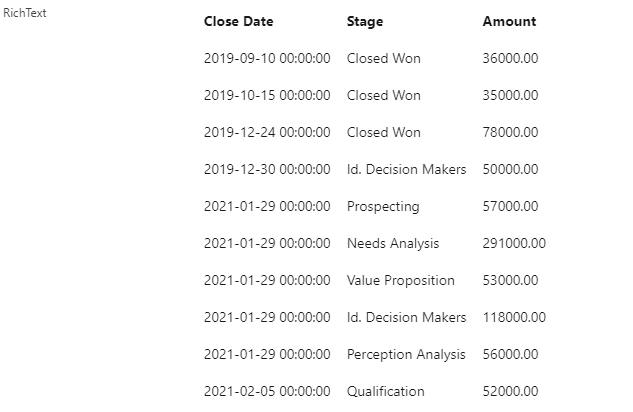
You get the idea. The open-ended nature of the configuration allows for virtually endless permutations on this, bringing the power of reporting tools directly to fields on a record page.
Let’s swap over to the code, because I think it’s a nice ode to something I wrote two years ago in A Year In Open Source:
I found again and again while working on issues the difference between good and bad architecture… when the plumbing was good, I was able to move things around and easily refactor - even when this involved hundreds of changes across dozens of files
Luckily, only a few files needed to be changed to add in this functionality, but the ease with which everything came into being reminded me: I don’t always get architecture right, but in revisiting existing architecture, it’s always easy to see when I did, because adding additional functionality in those cases is always easy.
private without sharing class GroupByCalculator extends DelimiterCalculator {
private final GroupingFormatter formatter;
private final System.Comparator<SObject> sorter;
private final RollupCalculator innerCalculator;
private final List<String> fieldNames = new List<String>();
private GroupByCalculator(
Rollup.Op op,
SObjectField opFieldOnCalcItem,
SObjectField opFieldOnLookupObject,
Rollup__mdt metadata,
SObjectField lookupKeyField
) {
// ...
}
public override void performRollup(List<SObject> calcItems, Map<Id, SObject> oldCalcItems) {
// ceremony section - curry the values from this to the inner calculator
this.innerCalculator.setEvaluator(this.eval);
this.innerCalculator.setFullRecalc(this.isFullRecalc);
this.innerCalculator.setCDCUpdate(this.isCDCUpdate);
this.innerCalculator.setHasAlreadyRetrievedCalcItems(this.hasAlreadyRetrievedCalcItems);
this.innerCalculator.parentIsoCode = this.parentIsoCode;
this.innerCalculator.isMultiCurrencyRollup = this.isMultiCurrencyRollup;
this.winnowItems(calcItems, oldCalcItems);
calcItems.sort(this.sorter);
Map<String, List<SObject>> groupingStringToItems = new Map<String, List<SObject>>();
for (SObject item : calcItems) {
String currentGrouping = '';
for (Integer index = 0; index < this.fieldNames.size(); index++) {
String fieldName = this.fieldNames[index];
Boolean isFirst = index == 0;
Boolean isLast = index == this.fieldNames.size() - 1;
Object groupingVal = item.get(fieldName);
if (groupingVal == null) {
groupingVal = '(blank)';
}
currentGrouping += this.formatter.getGroupingColumn(fieldName, groupingVal, isFirst, isLast);
}
List<SObject> groupedItems = groupingStringToItems.get(currentGrouping);
if (groupedItems == null) {
groupedItems = new List<SObject>();
groupingStringToItems.put(currentGrouping, groupedItems);
}
groupedItems.add(item);
}
String newGroupingValue = this.formatter.getGroupingStart();
for (String groupingKey : groupingStringToItems.keySet()) {
this.innerCalculator.setDefaultValues(this.lookupRecordKey, RollupFieldInitializer.Current.getDefaultValue(this.opFieldOnCalcItem));
this.innerCalculator.performRollup(groupingStringToItems.get(groupingKey), oldCalcItems);
this.innerCalculator.setReturnValue();
newGroupingValue += this.formatter.getGroupingRowStart(groupingKey) + this.innerCalculator.getReturnValue() + this.formatter.getGroupingRowEnd();
}
this.returnVal = String.isBlank(newGroupingValue) ? null : this.formatter.getGroupingEnd(newGroupingValue);
}
// ... plus one helper method used by the constructor
}In essence — given a GroupingFormatter, take another instance of RollupCalculator and iterate over each grouping, formatting the resulting value by field along the way. There are only two instances of GroupingFormatter — one which takes in the start and end delimiters shown in the config screenshots — and the formatter for table formatting:
private interface GroupingFormatter {
String getGroupingStart();
String getGroupingColumn(String fieldName, Object groupingValue, Boolean isFirst, Boolean isLast);
String getGroupingRowStart(String groupingKey);
String getGroupingRowEnd();
String getGroupingEnd(String groupByString);
}
private class DefaultGroupingFormatter implements GroupingFormatter {
private final String delimiter;
private final Rollup__mdt metadata;
public DefaultGroupingFormatter(Rollup__mdt metadata, String delimiter, Schema.SObjectField opFieldOnLookupObject) {
this.metadata = metadata;
this.delimiter = delimiter;
this.setupDelimiters(opFieldOnLookupObject);
}
public String getGroupingColumn(String fieldName, Object groupingValue, Boolean isFirst, Boolean isLast) {
return String.valueOf(groupingValue) + this.delimiter;
}
public String getGroupingStart() {
return '';
}
public String getGroupingRowStart(String groupingKey) {
return this.metadata.GroupByRowStartDelimiter__c + groupingKey;
}
public String getGroupingRowEnd() {
return this.metadata.GroupByRowEndDelimiter__c;
}
public String getGroupingEnd(String groupByString) {
return groupByString.removeEnd(this.getGroupingRowEnd());
}
private void setupDelimiters(Schema.SObjectField opFieldOnLookupObject) {
if (this.metadata.GroupByRowEndDelimiter__c == null) {
Boolean isRichText = opFieldOnLookupObject.getDescribe().isHtmlFormatted();
this.metadata.GroupByRowEndDelimiter__c = isRichText ? '<br>' : '\n';
}
if (this.metadata.GroupByRowStartDelimiter__c == null) {
this.metadata.GroupByRowStartDelimiter__c = '• ';
}
}
}
private class TableGroupingFormatter implements GroupingFormatter {
private final Map<String, Schema.SObjectField> fieldNameToToken;
private final Schema.SObjectField targetField;
private final Set<String> columnHeaders = new Set<String>();
private final String tdOpen = '<td>';
private final String tdClose = '</td>';
private final String thOpen = '<th>';
private final String thClose = '</th>';
private final String trOpen = '<tr>';
private final String trClose = '</tr>';
public TableGroupingFormatter(Schema.SObjectField targetField) {
this.fieldNameToToken = targetField.getDescribe().getSObjectType().getDescribe().fields.getMap();
this.targetField = targetField;
}
public String getGroupingColumn(String fieldName, Object groupingValue, Boolean isFirst, Boolean isLast) {
String prefix = isFirst ? this.trOpen : '';
String suffix = isLast ? this.trClose : '';
this.columnHeaders.add(prefix + this.thOpen + this.fieldNameToToken.get(fieldName).getDescribe().getLabel() + this.thClose);
if (isLast) {
this.columnHeaders.add(this.thOpen + this.targetField.getDescribe().getName() + this.thClose + suffix);
}
return prefix + this.tdOpen + String.valueOf(groupingValue) + this.tdClose + suffix;
}
public String getGroupingStart() {
return '<table>' + String.join(this.columnHeaders, '');
}
public String getGroupingRowStart(String groupingKey) {
return groupingKey.replace(this.trClose, '') + this.tdOpen;
}
public String getGroupingRowEnd() {
return this.tdClose + this.trClose;
}
public String getGroupingEnd(String groupByString) {
return groupByString + '</table>';
}
}Is this an ideal solution? Probably not. But it’s clean. Both inner classes are contained in 85 lines of code. There’s very little ambiguity about what each formatting method is doing. The calculator instance asks the formatter how to space out each column and row. It delegates the calculation to an inner calculator instance. In summary, there’s not a ton of net-new code. It was really lovely working on this feature, as a result; it felt self-contained, and came together really nicely.
Architectural Highlight 2: Query Parsing
Salesforce uses SOQL (Salesforce Object Query Language) for a querying language, which in most respects can be thought of as a subset of SQL:
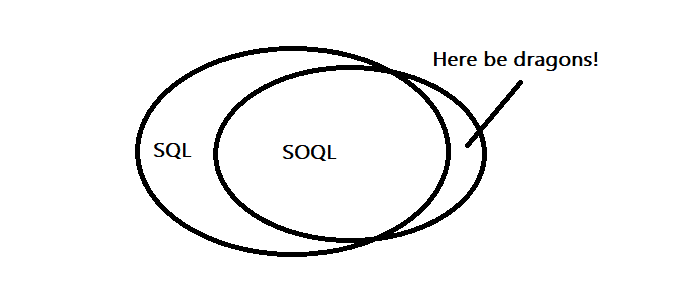
Like SQL, SOQL queries can be refined through the operative where clause:
SELECT Id
FROM Account
WHERE SomeField = TRUEWhere (pun intended) this gets interesting is that many Apex Rollup users can supply a similarly structured “where clause” to filter which records end up getting rolled up to parent-level field(s). Because conditional statements can be nested, they can modeled as a graph:
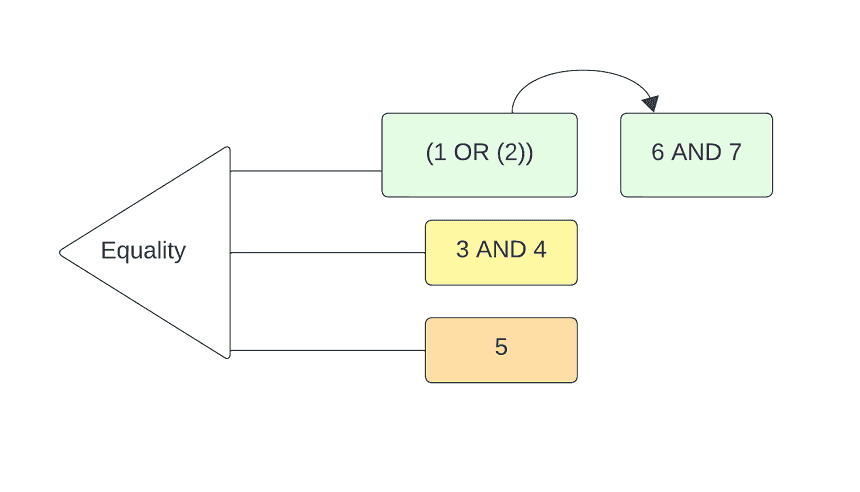
I say “interesting,” but in reality this was a problem that I preferred to not solve during the first year of building Apex Rollup. It was an instant feature request — within a day of launching — and one that I had backed down from including in the MVP due to the added complexity the parsing of these statements would entail.
There were two reasons I originally held back on including the ability to filter down children records using a string-based where clause:
- scalability: one of the central governing limits for Salesforce is based off of bulkifying queries being performed. Complicated where clauses — basically anything with a complicated cardinality, where indexed fields aren’t being considered — can take a long time, or worse, throw uncatchable limit exceptions when applied against large data volume tables (anything beyond hundreds of thousands of records). Since these clauses can be input through configuration, without code-based changes, that means that a poor-performing where clause (if actually applied) could break previously working code
- performance: perhaps a nuanced take on “scalable,” but here I differentiate between the possibly-broken case beyond which scaling ceases to apply, and the actual “feel” of using the application. The faster it runs, the less perciptible to the user that there’s an underlying process occurring
Because there are many common clauses that don’t actually require querying to perform, I became enamored with the idea of in-memory filtering by comparing each record to the where clause in question. There were several additional advantages (beyond not needing to query) to this approach that made it attractive to me:
- it gives the ability to “short circuit” any given rollup or set of rollup operations if there are no matching records, saving CPU time and system resources
- it allows larger batches of records to be processed without having to fussily concatenate potentially competing where clauses (and the caveats talked about in the “scalability” point above)
- once more on the topic of performance: it’s frequently faster to filter records in-memory than it is for the database layer to do the filtering
I think you can see how my own reticence came to bite me when you look at how the parsing code was originally structured:
private List<String> getSoqlWhereClauses(String localWhereClause, Schema.SObjectType calcItemSObjectType) {
List<String> localSplitWheres = localWhereClause.split('( and | AND | OR | or )');
this.reconstructImproperlySplitClauses(localSplitWheres, localWhereClause);
this.recurseForNestedConditionals(localSplitWheres, calcItemSObjectType, localWhereClause);
return localSplitWheres;
}This wasn’t my finest effort. I’ll be the first to admit that. reconstructImproperlySplitClauses() as a method name probably screams that loud and clear. But for years, I shied away from going back to refactor the underlying mess, because I was busy with feature requests — and the parsing “worked”, for the most part. Earlier this year, though, a few issues were logged against the project that made it clear that for more complicated where clauses — particularly those with paranthetically nested conditional statements — the existing parser wasn’t going to cut it.
Here’s an example where clause that demonstrates why splitting on conjoining words is fraught with the potential for failure:
FirstCondition = TRUE AND (SomeValue = 'this or that' OR AnotherValue = 1)Part of the challenge with the abbreviated approach shown above is with the improper splitting of “this or that” as though it were a clause in and of itself. The other challenge is that there’s quite a bit of string indexing necessary to relate SomeValue = 'this or that' to AnotherValue = 1; then there’s the bit of string indexing to see how that nested clause relates to the outer clause. Because there’s no theoretical limit on nested clauses, this string indexing can get quite messy.
In general, parsing a string like this is what I would describe as one of the bigger indictments of procedural programming; it’s easy to describe what we’re trying to do, but the codified version of it without taking advantage of principles like abstraction ends up an unreadable and incomprehensible mess. Let’s let objects come to the rescue!
Examining Some Failing Tests
But first, some failing tests:
@IsTest
static void nestedConditionalsWork() {
String whereClause = '(
(IsActive = TRUE) OR
(IsActive = FALSE AND FirstName = \'One\') OR
(IsActive = FALSE AND FirstName LIKE \'Special%\') OR
(FirstName = \'a\' AND AboutMe = \'b\') OR (FirstName = \'b\')
)';
User target = new User(IsActive = false, FirstName = 'One');
RollupEvaluator.WhereFieldEvaluator eval = new RollupEvaluator.WhereFieldEvaluator(whereClause, target.getSObjectType());
validateQuery(User.SObjectType, whereClause);
System.assertEquals(true, eval.matches(target));
System.assertEquals(true, eval.matches(new User(IsActive = true)));
System.assertEquals(true, eval.matches(new User(IsActive = false, FirstName = 'SpecialK')));
System.assertEquals(true, eval.matches(new User(FirstName = 'a', AboutMe = 'b')));
System.assertEquals(true, eval.matches(new User(FirstName = 'b')));
System.assertEquals(false, eval.matches(new User(IsActive = false, FirstName = 'c')));
}Those asserts aren’t an exhaustive list of all combinations, but they were enough to prove that the prior version of the code wasn’t quite working properly. Here’s another example of a test that I was basically able to copy + paste from the where clause of the GitHub issue that started me down this refactoring:
@IsTest
static void nestedConditionalsWorkWithSomeMatchingInnerClauses() {
// this clause came verbatim from a GitHub issue
// space after the parentheses and all
String whereClause = '(StageName = \'one\' AND LeadSource IN (\'Web\', \'Phone\') ) OR (LeadSource in (\'Web\', \'Phone\') AND StageName = \'two\')';
Opportunity target = new Opportunity(StageName = 'one', LeadSource = 'Web');
Opportunity secondMatch = new Opportunity(StageName = 'two', LeadSource = 'Phone');
RollupEvaluator.WhereFieldEvaluator eval = new RollupEvaluator.WhereFieldEvaluator(whereClause, target.getSObjectType());
validateQuery(Opportunity.SObjectType, whereClause);
System.assertEquals(true, eval.matches(target));
System.assertEquals(true, eval.matches(secondMatch));
System.assertEquals(false, eval.matches(new Opportunity(StageName = 'three', LeadSource = 'Web')));
}Having a few failing tests under my belt gave me the confidence I needed in order to proceed into the unknown — essentially, deleting all of the existing parsing code, and starting over.
Correctly Modeling The Problem
This time around, I wanted to take a properly object-oriented approach to creating the conditions such that the end result wasn’t a List<String>, but instead, something I’ve taken to calling List<WhereCondition>:
private abstract class WhereCondition {
public virtual Boolean isOrConditional() {
return false;
}
public abstract Boolean matches(Object calcItem);
}Remember when I showed that little superset for SOQL that didn’t overlap with the SQL part of the Venn diagram? One part of that “here be dragons” superset area involves negations. In SQL, a NOT negation occurs like such:
SELECT Id
FROM tableName
WHERE condition NOT LIKE 'sometextandwildcards%'In SOQL, the same negation is expressed like such:
SELECT Id
FROM tableName
WHERE NOT (condition LIKE 'sometextandwildcards%')Crucially, the paranthetical statement can also be a list of statements, or nested statements. So, to begin with, we can introduce the concept of a negated condition:
private class NegatedCondition extends WhereCondition {
private final WhereCondition innerCondition;
public NegatedCondition(WhereCondition innerCondition) {
this.innerCondition = innerCondition;
}
public override Boolean matches(Object item) {
return !this.innerCondition.matches(item);
}
}Then, to represent all of the other paranthetical cases, we can introduce the concept of a nested conditional:
private virtual class ConditionalGrouping extends WhereCondition {
protected final List<WhereCondition> innerConditions;
public ConditionalGrouping(List<WhereCondition> innerConditions) {
this.innerConditions = new List<WhereCondition>(innerConditions);
}
public virtual override Boolean matches(Object calcItem) {
// there are two versions of "matches":
// - one for conditionals chained with AND
// - one for conditionals chained with OR
// the implementation is boring, and ellided
}Notice, going back to the NotCondition that because it takes in the base, WhereCondition type, it can be used as was described previously; to negate either a singular condition, or a ConditionalGrouping without issue. Lastly, there’s the object encapsulating the actual field-level criteria:
private class WhereFieldCondition extends WhereCondition
private Boolean isOrConditional = false; // maps to this.isOrConditional()
public WhereFieldCondition(String fieldName, String criteria, String value, Schema.SObjectType sObjectType) {
this(fieldName, criteria, new List<String>{ value }, sObjectType);
}
public WhereFieldCondition(String fieldName, String criteria, List<String> values, Schema.SObjectType sObjectType) {
// set up mapping between the field, criteria, and the values being compared
}
}Which brings us to the (very) scary part where a very big string of conditions is actually parsed into these objects. I showed you what the old version of that code started with — splitting on the words “and” and “or”. As stated already, that approach was inherently flawed. The new approach still relies on recursion, but primarily enables the string to be “walked” front to back:
private List<WhereCondition> recursivelyCreateConditions(String localWhereClause) {
if (localWhereClause.startsWith('(') && localWhereClause.endsWith(')')) {
localWhereClause = localWhereClause.substring(1, localWhereClause.length() - 1);
}
// [ellided cleanup section here]
List<String> words = localWhereClause.split(' ');
List<WhereCondition> conditionals = new List<WhereCondition>();
for (Integer index = 0; index < words.size(); index++) {
Boolean isOrConditional = index == 0; // first conditional is always an "or"
Boolean isNegated = false;
// [ellided - short section that sets isNegated and isOrConditional for recursive section]
if (word.startsWith('(')) {
// recursive branch
List<WhereCondition> innerConditions = this.recursivelyCreateConditions(word);
WhereCondition condition = isOrConditional
? new OrConditionalGrouping(innerConditions)
: new ConditionalGrouping(innerConditions);
if (isNegated) {
condition = new NegatedCondition(condition);
}
conditionals.add(condition);
continue;
}
// nonrecursive branch - code that creates WhereFieldConditions
if (word.equalsIgnoreCase('not')) {
isNegated = true;
word = words[++index];
} else if (word.equalsIgnoreCase('or')) {
isOrConditional = true;
word = words[++index];
} else if (word.equalsIgnoreCase('and')) {
isOrConditional = false;
word = words[++index];
}
String fieldName = word;
String criteria = words[++index];
if (criteria.equalsIgnoreCase('not') && words.size() - 1 > index) {
String potentialNextToken = words[index + 1];
if (potentialNextToken.equalsIgnoreCase('in')) {
criteria += ' ' + potentialNextToken;
index++;
}
}
// here, we handle IN clauses, and actual text values
String value = words[++index];
if (criteria.endsWithIgnoreCase('in')) {
while (value.endsWith(')') == false) {
value += ' ' + words[++index];
}
} else if (value.startsWith('\'') && value.endsWith('\'') == false) {
String tempVal = value;
while (tempVal.endsWith(')')) {
tempVal = tempVal.removeEnd(')');
}
while (tempVal.endsWith('\'') == false) {
tempVal += ' ' + words[++index];
}
value = tempVal;
} else {
value = value.removeEnd(')');
}
WhereFieldCondition simpleCondition = this.createConditionsFromString(fieldName, criteria, value);
if (index < words.size() - 1) {
Integer forwardCounter = index;
String nextToken = words[++forwardCounter];
isOrConditional = nextToken.equalsIgnoreCase('or');
}
simpleCondition.isOrConditional = isOrConditional;
// the cast on the back half of the ternary is necessary for "reasons"
conditionals.add(isNegated ? new NegatedCondition(simpleCondition) : (WhereCondition) simpleCondition);
}
return conditionals;
}Is this the best code? No — certainly not. But splitting on spaces (caveat: most query languages don’t require spaces) feels like the right balance as far as supporting conditionals without requiring a character-by-character parser. There are definitely still optimizations to how these objects can be represented — to me, the isOrConditional() method is a code smell I haven’t quite refactored out into its own object. It, as a concept, is certainly not as clean as the NegatedCondition.
There are three different layers where an OR can occur:
- at the outermost level, while evaluating all conditions:
Field1 = 'one' OR Field2 = 'two' OR Field3 = 'three', for instance - as a nested conditional:
Field1 = 'one' AND (Field2 = 'two' OR Field3 = 'three') - as the pre-requisite to a nested conditional:
Field1 = 'one' OR (Field2 = 'two' AND Field3 = 'three')
I’m confident that there’s another refactoring to be applied here; I just haven’t gotten around to it yet. I also plan to open source this parser separate from Apex Rollup.
Possible Algebraic Optimizations
There’s an interesting set of algebraic possibilities that I also haven’t accounted for in the current version of the code. To demonstrate, consider the following clause:
1 AND (2 OR 3) AND (2 OR 4) AND (2 OR 5)With the current code structure, the object hierarchy looks like:
WhereFieldConditionthat encapsulates 1ConditionalGroupingthat encapsulates 2 and 3 asWhereFieldConditions. 2’sthis.isOrConditionalis set to trueConditionalGroupingthat encapsulates 2 and 4 asWhereFieldConditions. Same thing here: 2 is once more set up as an or conditionalConditionalGroupingthat encapsulates 2 and 5 … etc
An obvious optimization would be to combine like terms by moving the 2 out:
1 AND (2) AND (3) AND (4) AND (5)Which could also bring out the obvious optimization that a conditional grouping with only one WhereFieldCondition can be swapped for the WhereFieldCondition (or NegatedCondition ?) itself.
I’ve chosen to do neither of these things, under the (possibly mistaken) belief that the complexity they’d add to the logic would cost more than the CPU time they’d save. I'd love to be proven wrong on that!
Fun Architectural Highlight 3: Memory Management
I’ve been working with a few Independent Software Vendors (ISVs) who’ve embedded Apex Rollup within their own applications. I’m indebted to them for helping to stress-test the application; particularly how it performs with tens of millions of records when full recalculations are being performed. There’s an upper bound in the low 7 digits whereby the amount of memory being dedicated to how the application tracks parallel calculations that can be related to the same parent record simply broke down, and that breakdown happens more quickly as more and more rollups are configured (which, primarily, happens outside of code).
This had the potential to limit people to recalculating single rollups at a time — which could be extremely time consuming — or preventing a full recalculation altogether. Quel désastre!
The code responsible for this paging problem was simple:
public without sharing virtual class RollupFullBatchRecalculator
extends RollupFullRecalcProcessor
implements Database.Stateful, Database.RaisesPlatformEvents {
// this set can, with enough records to process, overflow the heap by itself
protected final Set<String> statefulPreviouslyResetParents = new Set<String>();
}Yikes! To further complicate things, Salesforce as a platform is responsible for creating the equivalent of a cursor in SQL; you can query up to 50 million records in a “batch” context, but if there’s spillover between the cursor batches (in terms of how records related to a single parent are grouped), it becomes exponentially more difficult to know what to do with a subset of children records: eg, are they additions to a pre-existing value? Or are they the first-ever pieces of a now in-flight set of records?
To avoid this memory problem entirely, I came up with the following system:
- at the end of every batch, store the key associated with each of the parents that have been processed
- at the start of every batch, keep only the keys that the calculation records have associated with parent records from this batch (the key set itself is shared memory between all batches)
- if a parent record’s key isn’t present in the set, reset its value (assume it’s the first time the parent record has been seen) while performing a rollup; otherwise, treat it as though it’s already been reset
This system relies on the children-level records being ordered properly by parent key; it is, to my knowledge, the only way (without introducing a custom object to store intermediate results, which I’ve been loathe to do) to handle both:
- situations where a single parent record has more children than the Salesforce query limit for records (50k+)
- 8 digit+ data volume
I’m not opposed to changing up this approach. There are some good reasons for considering the introduction of (temporary) custom object records that get cleaned up at the end of a full recalculation. With the current approach, consider a MOST-based rollup operation where a single parent has more than 50k children records:
- Child 1, batch 1, rollup field = 1
- Child 2, batch 1, rollup field = 1
- Child 3, batch 1, rollup field = 1
- Child 4, batch 1, rollup field = 5
- … etc, but never more than two matches on a rollup field in any other batch
- Child 50001, batch n, rollup field = 2
- Child 50002, batch n, rollup field = 2
This particular rollup operation doesn’t scale well as a result if every child record is required to be present. The parent should get 1 as its rollup value, because there are 3 records that have that value, but the current architecture makes that difficult.
On the other hand, introducing a custom object here isn’t a panacea by itself. That approach adds a lot more complexity because each rollup operation essentially needs to be able to opt-in to knowing when it can’t simply rely on in-memory objects to compute the full rollup value, and the representation for what the “ideal memory state” should be will differ based on the rollup operation in question.
Going back to our MOST example, and keeping in mind that each batch cursor or chunk can contain a maximum of 2000 records, this would entail: a record per in-flight parent that looked like:
{
"key" : "parent1Key-MOST",
"operation": "MOST",
"value": {
"5" : "1",
"2" : "2",
// etc - unknown number of other keys
// paired to the count of their occurrences
"1" : "3"
}
}Whereas if we were performing a MIN operation, the value might instead look like:
{
"key" : "parent1Key-MIN",
"operation": "MIN",
"value": "1"
}So — for some operations (like MIN and MAX), keeping track of possible “winning” values between batches isn’t that complicated; for others (like MOST), it would entail quite a bit of additional bookkeeping. As a result, I’ve yet to bite off this particular piece of work.
Documentation Wrangling
Perhaps the biggest surprise of this year was the influx of issues related to documentation. I’d like to thank Bao Do in particular for taking the time over the past year to file a number of issues against Apex Rollup. His work in cross-checking the Wiki and Readme is much appreciated, and has led to a number of documentation improvements.
In a project where much of the power lies in configuration, keeping documentation (technical and non-technical!) up to date is a continual challenge. I’m appreciative to many of the people that have written in, emailed, and sent me messages about documentation suggestions. Keep them coming!
Wrapping Up
I keep finding new things to think about, and to build. There’s no shortage of great open source projects to contribute to — just time, and finding the right balance between the different things that make me tick. Here’s to hoping that as 2023 starts to wind down, you’re finding contentment and satisfaction in the things that make you tick; that these reflections and architectural deep-dives have given good food for thought.
As we head into 2024, I’m excited to see what new features and refactorings are still to come. Till next time!